Shortest path problem in unweighted graph
Breadth-first search (BFS) algorithm is one of two elementary graph algorithms that extensively used for graph traversal and searching problems.
The path searching problem in an unweighted graph
Let’s discuss a typical path searching problem where we start from the vertex “Source” and try to determine if there a path to the vertex “Destination” in a graph with the following properties:
- It is directed but the algorithm works well for undirected too.
- It is unweighted, i.e. edges have no cost.
- It has unrealistically small number of vertices.
The 2 main problems in interest are the Breadth-first search (BFS) and Depth-first search (DFS).
BFS
Let’s review some properties of BFS:
- The algorithm running from a node will visit all of its neighbors first before running from the next node.
- The implementation of BFS often employs the queue data structure.
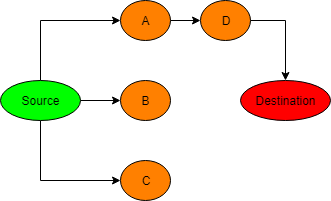
Here is an example of an application running BFS algorithm (-> represents ‘visit’)
1. Step 1: source -> A, and add A to the queue
2. Step 2: Source -> B, and add B to the queue
3. Step 3: Source -> C, and add C to the queue
4. Step 4: Dequeue A, A -> D, and add D to the queue
5. Step 5: Dequeue D, D -> Destination (Destination is found)
At step 5, destination is found and the path is Source -> A -> D -> Destination.
DFS
On the other hand, DFS has these properties:
- The algorithm running from a node will visit all of the nodes in 1 branch before moving to next branch.
- DFS algorithm does not use queue but often implemented with recursion.
Here is an example of an application running DFS algorithm:
1. Step 1: source -> A
2. Step 2: A -> D
3. Step 3: C -> Destination (destination is found)
In both algorithms, we will eventually find the correct path from a given Source node to the Destination node. Additional, if the source node cannot reach the destination, both algorithms can help to detect this.
However, in most real-life applications, we are more interested in the shortest path problem and not just to find the path. This is where BFS prevails.
The Shortest Path Problem in Unweighted Graph
In the diagram below, there is more than 1 path from Source to Destination.
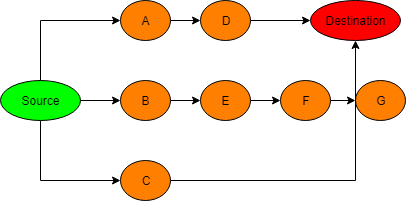
Using DFS, we can find the first path but we cannot be sure this is shortest and hence must continue the search until all paths are reached (early termination is possible, though, when the current branch is already longer than current shortest path)
Source -> A -> D -> Destination (update this path as current shortest path)
Source -> B -> E -> F (early terminate because the branch length is already more than current shortest path)
Source -> C -> Destination (update the shortest path)
For BFS, we can immediately stop once Destination is found as this is clearly the shortest path
Source -> A, and add A in queue
Source -> B, and add B in queue
Source -> C, and add C in queue
Dequeue A, A -> D, and add D in queue
Dequeue D, D -> E, and add E in queue
Dequeue C, C -> Destination
In most problems where we try to model as graphs, the number of vertices is huge and hence we need to consider the efficiency.
The complexity of both algorithms are actually the same in the worst case, i.e. O(N+E). However, BFS is almost always more efficient for the shortest path problem in unweighted graph.
wikilink: an BFS application
Let’s say we start from the wiki page “Shortest path problem”, and follow the link to the page “graph”. Then from page “graph”, we can find the link to the page “discrete mathematics”.

We say that there is a chain of links from the page “Shortest path problem” to the page “discrete mathematics”, i.e. Shortest path problem => graph => discrete mathematics.
Again, a more interesting question is to find the shortest chain that go from a wiki link to another. Also, we want to verify if the distance between 2 wiki pages follow the idea Six degrees of separation. This problem has been mentioned in Web Scraping with Python.
wikilink is a web-scraping application to implement the idea, i.e. to find the minimum number of links between 2 given wiki pages. I modeled this problem with an unweighted graph where pages are vertices.
Infinite loop problem
One of the problem is where there is cycle which means we revisits the page that has been visited. This can lead to the infinite loop and run forever. This is often truly a pain of many many web scraping application.

The way wikilink takes care of this problem is to use a set to store the pages that have been seen. However, it could happen that number of links are so huge that the we run out of memory to store in the set. Hence we define a variable “limit” which is the maximum number of separation from the source link the the page that we want to examine.
Algorithm Flow
- We first define a set to keep track of seen wiki pages and a queue
- Given a source wiki page, wikilink store the source into the set and the queue
- We perform a “while loop” to keep extracting from the queue:
- we check if this page is the destination page.
- If yes: we return number of separation from the source to this page.
- else: Scraping the current page to get the outbound links from this page
- We check from the set if a page that has been visited and store these links into the set and the queue if it is not in the set yet.
- we check if this page is the destination page.
We continue until the destination page is found or when it runs out of our limit. If there is no more links in the queue but destination page has not been found, we conclude that there is no chain from the source to the destination.




Leave a comment