Clock synchronization algorithms
Synchronizing time in distributed systems is crucial to ensure that the interactions between members in the system are correct and fair. For instance, let’s say a server A in a reservation system receives a request to purchase a flight ticket with seat S, server A locally logs the transaction at time T. Server A also informs server B that seat S has been taken. Server B also logs the information with its local timestamp that less than T. When another server C queries both A’s and B’s logs, it could be confused that a client purchased a ticket at A after the seat has taken and could further take incorrect actions.
In general, clock synchronization algorithms address 2 main questions:
- How a computer synchronizes with an external clock and
- How computers in distributed systems synchronize with each other.
Clock in a single system
Before we dive into a distributed system, let’s discuss the clock in a single system. Any computer has a device called clock or timer to keep track of time. A clock consists of 2 registers, i.e. a counter and a holding register, and a quartz crystal oscillator that can generate an accurate periodic signal, typically in the range of several hundred MHz to a few GHz and can be amplified to a range of several Ghz using electronics.
The clock operates in 2 modes:
-
One-short mode: When the clock is started, it copies the value of the holding register into the counter. Every time the crystal oscillates and sends a signal into the counter, the counter decrements by 1. When the counter gets to zero, it causes a CPU interrupt and stops until it is started again by the software. These periodic interrupts are called clock ticks. The interrupt frequency can be controlled by software.
-
Square-wave mode: after getting to zero and causing the interrupt, the holding register is automatically copied into the counter, and the whole process is repeated again indefinitely.
To prevent the current time from being lost when the computer’s power is turned off, most computers also have a battery-backed CMOS RAM such that date and time can be saved and read at startup. If no information is present, the system will ask the user to enter the date and time which will be converted into the number of clock ticks since a known starting date, i.e. 12 A.M. UTC on Jan. 1, 1970, in Unix. At every clock tick, the interrupt-service procedure updates the clock by 1.
The standard worldwide time is called Universal Coordinated Time (UCT). Computers around the world can synchronize their clocks with Internet UTC servers for up to milliseconds precision or with satellite signals for up to sub-microsecond precision.
Clock in distributed systems
Clock skew and clock drift
In a distributed system, each system’s CPU has its own clock which runs at a different rate. The relative difference in clock value is called clock skew.
On the other hand, the relative difference in clock frequency is called clock drift and the difference per unit time from a perfect reference point is clock drift rate, this rate is affected by many factors such as temperature.
As an analogy, clock skew is akin to the difference in distance between 2 cars on the road while clock drift is the difference in speed. A non-zero clock skew implies clocks are not synchronized and a non-zero clock drift will result in skew to increase eventually.
Once we know the clock is drifting away from the reference clock, we can change the clock value. However, it is not a good idea to change the clock backward, because going backward can violate the ordering of events within the same process, for example, an object file computed after the time change will have the time earlier than the source which was modified before the clock changed. It is better to adjust the clock gradually by changing the rate of interrupt requests.
External and Internal Synchronization
We denote C(i) as the value of timer I at UTC time t.
Some clock synchronization algorithms try to achieve precision or internal synchronization - to keep the deviation of clock value of any 2 machines in a distributed system within bound D at all time, i.e. Berkeley algorithm
|C(i) – C(j)| < D
Some algorithms try to achieve accuracy or external synchronization - to keep each clock value within a bound R from value S of an external clock, say UTC server or an atomic clock at all time, i.e. Cristian’s algorithm, NTP, etc.
|C(i) – S| < R
If clocks in a system are accurate within R, this will imply precision or internal synchronization within bound D=2*R. However, internal synchronization does not imply external synchronization, i.e. the entire system may drift away from the external clock S.
Of course, the ideal situation is when C(i)=S or D=R=0, but this is not possible because clocks are subject to clock skew and drift.
When to synchronize?
Hardware clock usually defines its’ Maximum Drift Rate (MDR) relative to the reference UTC time. Imagine that fast and slow clocks that deviate from the UTC in opposite direction with the same MDR, at any unit time, they will deviate by 2*MDR from each other. If we want to guarantee a precision D, say clocks cannot differ more than D seconds, we need to synchronize the clocks at least every D/(2*MDR) time units since time = distance/speed.
Christian’s algorithm
A naive external synchronization will look like this:
- Every host in the system sends a message to an external server to check the time
- Server checks local clock to find time t and responds a message with time t to hosts
- Each host sets their clocks to t
The problem is that when the host receives the message from an external server, the time has moved and caused the time inaccurately. In distributed systems, the members follow the asynchronous system model. Since inaccuracy is a result of message latencies and latencies are unbounded in an asynchronous system, the inaccuracy cannot be bounded either.
Christian’s algorithm modifies step 3 above Host A measures the round-trip-time RTT of message exchange. The actual time at A when it receives response is between [t , t + RTT ]. Host A sets its time to halfway through this interval:
t + RTT/2
The error
In order to calculate the error, we incorporate the minimum latency l1 from A to S and l2 from S to A. l1 and l2 depend on operating system overhead, i.e. buffer messages, TCP time to queue messages, etc.
So now, the time at A when it receives response is within [t + l2, t + RTT - l1]. Host A sets its time to halfway through this interval:
t + (RTT + l2 - l1)/2
Error is at most (RTT - l2 - l1)/2, the longer your RTT is, the more error. Christian’s algorithm did not specify a way to increase or decrease the speed of the clock but allow us to change the speed of clock. If error is too high, RTT can be taken multiple times and average them.
Network Time Protocol
Network Time Protocol (NTP) servers organized in a hierarchical tree-like system. Each level of this hierarchy is termed a stratum and is assigned a number starting with zero for the reference clock at the top, i.e. the lower the stratum, the server is supposed, but not always, to be more accurate.
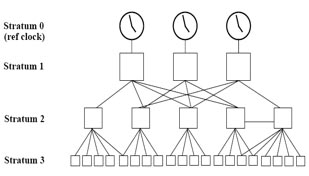
When a particular client synchronizes with a server, the one with higher stratum level, whether it is client or server, will adjust its’ stratum level to become just one level higher than the other. For instance, if server is stratum-k and client is stratum-k+2 , then client will adjust itself to stratum-k+1.
In NTP, a client will estimate the message delay when it tries to synchronize with the server using the following algorithm:
-
The client polls NTP server to start
-
The server responds with a message to the client and records the local timestamp t1
-
The client receives the message and records as t2
-
The client sends the second message to the server and records at t3
-
The server receives the message and records it as t4 with local clock
-
The server sends the values t2 and t4 to the client
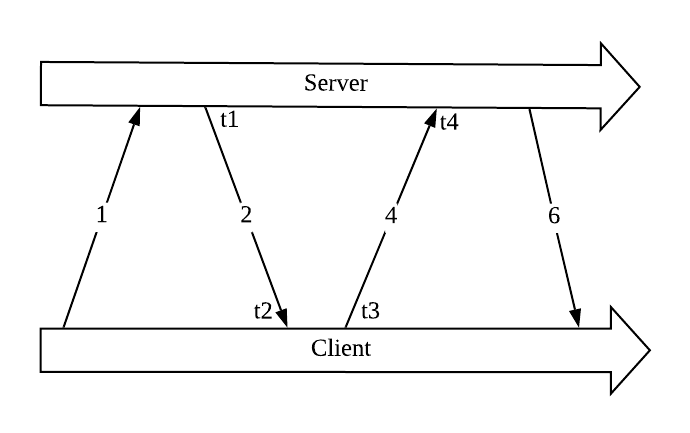
The client knows the values of t1, t2, t3, t4 and hence can calculate its’ offset theta relative to server, and round-trip delay delta:
θ = (t2 – t1 + t3 – t4)/2
𝛿 = (t3 - t2) + (t4 - t1)
The client calculates (θ,𝛿) a number of times, and use the minimum round-trip delay as the best estimation for the delay between two hosts, the associated offset is the most reliable estimation of the offset. Let’s discuss how reliable this estimation is.
The error
we denote the real offset as real_offset, say the client is ahead of server by real_offset, and suppose one-way latency of first and second messages are l1 and l2, then:
t2 = t1 + l1 + real_offset
t4 = t3 + l2 – real_offset
Subtracting the second equation from the first
real_offset = (t2 – t4 + t3 – t1)/2 + (l2 – l1)/2
=> real_offset = θ + (l2 – l1)/2
=> |real_offset - θ| < |(l2 – l1)|/2
The offset error is bounded by the non-zero RTT. We cannot get rid of error as long as message latencies are non-zero.
The Berkeley algorithm
The Berkeley algorithm is an internal synchronization algorithm. It is sufficient that machines in the system to synchronize time but not necessary for them to synchronize with an external clock.
-
A particular time server poll each machine in the system to ask their time.
-
The machines respond with how far ahead or behind from the server.
-
The server computes the average and tells each machine to adjust the clock.
Reference Broadcast Synchronization (RBS)
RBS is another internal synchronization algorithm. The algorithm does not try to sync the time with an external clock, in fact, it does not assume there is an external clock with accurate time.
-
A transmitter broadcasts a reference message to all receivers.
-
Each receiver receives and records the message at time C(i) with its’ local clock, then exchanges C(i) with other nodes.
-
Each nodes calculate its own clock value relative to another, it can simply store the value and also does not need to adjust its clock which saves energy.
Leave a comment