Leader election algorithms
Many distributed systems require a leader to coordinate members. For instance, usually a group of replicas will have 1 leader that receives reads from the client and then sends copy to others. The crashing of the leader can lead to data inconsistency. Next, what if the members cannot agree on the next leader, or even worse more than 1 server claims to be the leader. To keep the system consistent, we need to:
- Elect a leader and let everyone knows about this leader
- When this leader fails, some process can detect this and elect new leader through some election algorithm
Let’s consider a model of system of N processes, each has their unique ID since without any special characteristics, there is no way to select among them, and every process knows the ID of every other process. Leader election algorithms aim to:
- Elect one leader only among the non-faulty processes and all non-faulty processes agree on who the leader is.
- Any non-faulty process can call for an election but at most one election at a time. Multiple processes are allowed to call an election simultaneously but together must yield only a single leader. And finally The result of an election should not depend on which process calls for it.
- Safety (nothing bad happens): all non-faulty processes will either agree to elect a non-faulty process with the highest attribute, or elects none at all. The attribute can be anything, i.e. the highest process ID, highest IP address, etc.
- Liveness (something good eventually happens): the election will eventually terminate at which one of non-faulty processes will become leader. Liveness is achieved under the assumption of reliable message delivery.
The bully algorithm
The simplest algorithm is that the currently running highest ID process will suppress lower ID processes and become the leader, hence the name the bully algorithm. Since every process knows the ID of others:
- When a process finds the coordinator has failed via the failure detector:
- If it is the highest ID, it self-elects itself and sends a COORDINATOR message to inform other members; the election is completed.
- Otherwise it initiates an election by sending an ELECTION message to processes with higher ID than itself, including the failed leader.
- If it does not receive answer within the timeout, the process sends COORDINATOR message to all lower-ID processes to announce itself as leader and the election completed.
- If an answer received OK message from some higher process, it will just wait for COORDINATOR message. If none received after another timeout, it starts a new election run.
- A process that receives an ELECTION message replies with OK message to suppress lower ID processes, and starts its own leader election protocol (unless it has already done so).
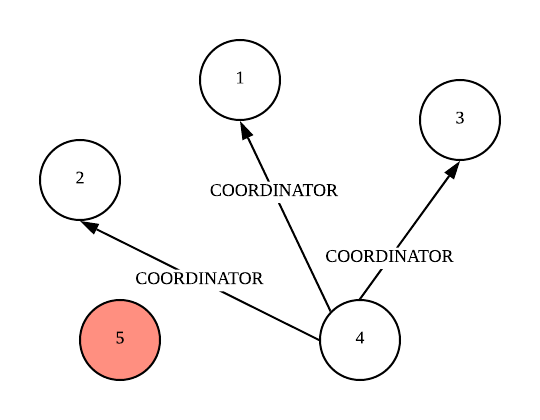
Let’s look at an example, node 2 detects the leader has failed and sends the “ELECTION” messages to every higher-id nodes.
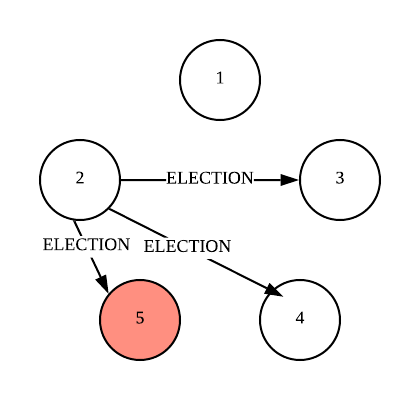
The non-faulty nodes 3 and 4 sends back OK messages to node 2, node 2 stops any action.
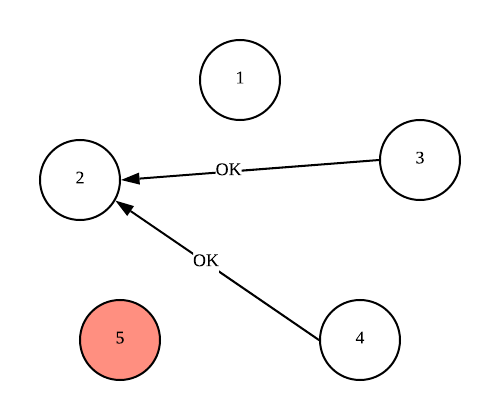
Now both nodes 3 and 4 sends ELECTION messages to nodes with higher ID than themselves, and receives respective OK messages from non-faulty higher ID nodes.
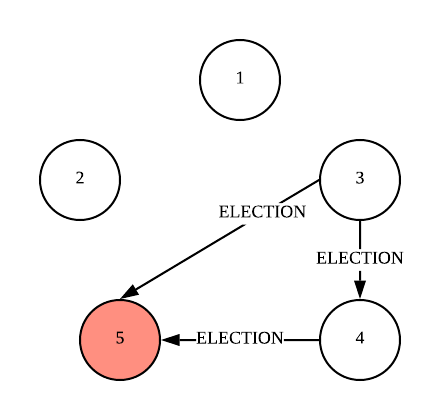
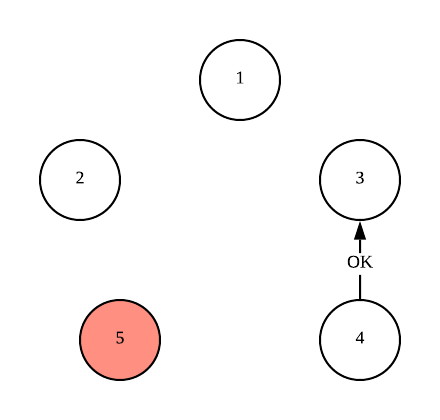
Now Node 4 does not receive OK message, and so it sends COORDINATOR message to all lower-ID processes to announce itself as new leader.
Analysis
The worst case happens when the election starts from the lowest-ID process, i.e. it sends (N-1) ELECTION messages to all the higher-ID processes. So the ith process sends (i-1) election messages, and the total messages are (N-1 + N-2 + … + 1) = O(N^2). On the other hand, the best situation is when the second-highest ID process detects leader failure and it only needs to send (N-2) COORDINATOR messages, no ELECTION message since there is no non-faulty higher-ID process than itself.
The Safety property cannot be met in some situations:
- It we replace the faulty leader with another process with the same ID, this new process will think that is has the higher ID. This process, together with the new process that also thinks that it currently has the highest ID via the election algorithm since the failure of the old leader; will send the COORDINATOR concurrently to announce themselves as the new leader. There are no guarantees on message delivery order, and the recipients of these messages may reach different conclusions on which is the coordinator process. Hence, Safety is achieved if no process is replaced.
- If the timeout in the step 2 above is not set accurately, i.e. a higher-ID process did not fail but sends message unusually slow causing the timeout at the algorithm initiator, this initiator then thinks that it is the non-faulty higher-ID process, and again we face the situation where more than 1 process claims to be the leader. So the Safety cannot be met in asynchronous system model where processes might be arbitrarily slow. However, in synchronous system model where the process execution speed and the message delivery time is bounded, and so we can set the timeouts such that above situation can be avoided, i.e. timeout is equal to the sum of the worst-case process execution speed and the worst-case message delivery time.
The Liveness condition can be met under the assumption of reliable message delivery, that is messages are eventually received at the correct destinations.
Chang and Roberts ring algorithm
In the ring algorithm, The system of N processes are organized in a logical ring, each process has a communication channel to the next process in the ring and messages are sent clockwise around the ring:
- Any process that discovers the old leader has failed (the initiator) initiates an ELECTION message containing its own ID to other nodes around the ring in clockwise;
- When a process receives an ELECTION message, it compares the ID in the message with its own ID:
- If the arrived ID is greater, it forwards the message.
- If the arrived ID is smaller and the process has not forwarded an ELECTION message earlier, it overwrites the message with its own ID, and forwards it.
- If the arrived ID matches its’ own ID, then the ID must be the greatest (the message has made a circle around the ring and has not changed). This process then sends an ELECTED message to its neighbor with its id, announcing the election result.
- When a process receives an ELECTED message, it records the new elected ID and forwards the message. when the ELECTED message returns to the newly elected leader, the leader discards that message, and the election is over.
When there are multiple initiators, each process remembers in cache the initiator’s ID of each ELECTION/ELECTED message it receives, it will suppress ELECTION/ELECTED messages of the initiator with lower ID or updates cache for the initiator with higher-ID. Hence, eventually, only the highest-id initiator’s election completes.
Another variation of ring algorithm is the initiator creates an empty list, add its own ID and then send around the ring, each non-faulty process subsequently appends its own ID to the list. When the list arrives back to the initiator, it knows the non-faulty highest-ID process, and send a another message around the ring to inform everyone about this who the new leader is.
Analysis
The worst case situation occurs when the initiator is the ring successor of the would-be leader. There are total of (3N-1) messages:
- (N-1) messages for ELECTION message to get from the initiator to would-be leader.
- N messages for ELECTION message to circulate around ring from the would-be leader without message being changed.
- N messages for ELECTED message to circulate around the ring.
The best case is when the initiator is the would-be leader, there are 2N messages:
- N messages for ELECTION message to circulate around ring from the would-be leader without message being changed.
- N messages for ELECTED message to circulate around the ring.
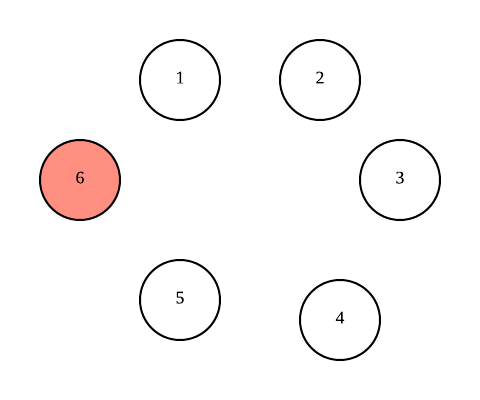
For example, in the diagram below, when node 6 fails, the best case situation is when node 5 initiates the election, and the worst case occurs when node 1 initiates.
It is clear that Safety is achieve since everyone knows about highest ID process as leader, since all IDs are compared and a process must receive its own ID back before sending an ELECTED message. The process with larger ID will not pass on the lower one, therefore it is impossible that both should receive their own ID back.
If there are no failures, we achieve Liveness since election eventually terminates. However, the Liveness is violated if the would-be leader failed after sending its ID, causing the ID to go round the ring forever, there are some proposals to fix this:
- The predecessor (or successor) of the would-be leader detects failure and start a new election run if they have received an ELECTION message but timeout waiting for an ELECTED message or after receiving the ELECTED messages. However, the predecessor (or successor) can also fail.
- After receiving ELECTED message with the would-be leader’s ID, the processes can detect failure of this leader via its own local failure detector in case this leader failed after sending the message. And so it can start a new run of leader election. However, we shall see in later chapter that failure detectors may not be both complete and accurate:
- Incompleteness means that the processes can fail to detect when the leader has failed, causing the a faulty leader being elected which is a violation of Safety property.
- Inaccuracy means that the processes detect a failed leader while it is in fact not failed, as a result, it will initiates a new election and run forever, which is a violation of Liveness property.
A bit of Consensus
We will not discuss consensus in details here and leave it for later chapter. However, it is important to emphasize that election is related to consensus. If we could solve election, then we could solve Consensus, for instance, we elect a process, use its ID’s last bit as the consensus decision. However, we will see later than consensus is impossible in asynchronous systems, and so election is impossible too.
In practice, we can apply Consensus protocols for election, i.e. each process proposes a value, everyone in group reaches consensus on some process P’s value, and this process P is the new leader. The most popular Consensus protocols are Paxos and Zap, they guarantee safety but only eventual liveness, i.e. not always guarantee that protocol will ever terminate. Several systems use Paxos or Zap for election, i.e. Google’s Chubby system, Apache Zookeeper, etc.
Leave a comment